Classic event sourcing has a rule: one aggregate, one stream, one consistency boundary. It is simple and it scales, but it is rigid. The moment you need an invariant that spans two aggregates, you are writing sagas and workarounds.
Dynamic Consistency Boundaries (DCB) are meant to remove that constraint. The recurring objection is that they are slow. So I built a small DCB framework in Go on top of Postgres and benchmarked the append path. All concurrency is handled in the database, not the application, so the Go side is stateless: you can run many instances in parallel and still get full consistency. And it is plain Postgres, so anyone can reproduce it.
What is wrong with classic event sourcing?
The aggregate is your consistency boundary. Strong consistency exists only inside one aggregate’s stream, enforced with a version number and optimistic locking. You get small transactions, no distributed locks, and clean concurrency control.
The cost is that the boundary is fixed at design time. You decide it while modelling your events: which event belongs to which stream. If two things must change together they have to share an aggregate, and a rule that spans separate aggregates cannot be enforced in one transaction. Getting it wrong means re-streaming events later, a migration you do not want to run on a live system.
What is DCB then?
DCB makes consistency a condition defined per command, as a query over the events, instead of a fixed boundary. You read the events your decision needs, record the position you read up to, and on append the store checks that no new matching events arrived in between. Same optimistic locking, dynamic boundary.
Events carry tags, and a boundary is a query over those tags. Boundaries therefore do not need to be known up front: a new requirement is a new query over tags that already exist, with no re-streaming. The one design-time commitment that remains is the tags themselves. Forget to tag something you later need, and you have to backfill it.
For the theory and the “Killing the Aggregate” talk behind it, see dcb.events.
The setup
The store is Scaleway Managed Database for PostgreSQL. I did not self-host Postgres on a VM; these are managed database nodes, so the numbers reflect the standard managed offering out of the box. Client to database round-trip was about 11 ms.
- A 10,000,000-event store.
- 64 concurrent writers by default, plus a sweep over the number of users.
- A real DCB append with
condition=check: the in-lock condition check runs. - Overlap = the fraction of writes aimed at one shared boundary. 0% means every writer hits its own entity, 100% means all hit the same one.
Two managed-database node types appear in the charts:
- Small node: PLAY2-PICO, 1 vCPU, 2 GB RAM. About €10/month.
- Big node: general-purpose, 32 vCPU, 128 GB RAM. About €1,580/month (€2.17/hour).
The small node does about 2,800 appends/s with staging; the big node reaches about 5,000/s. Roughly 150x the price for under 2x the throughput. The ceiling is the database write path, not the core count.
One caveat before the numbers: absolute throughput varied about 3x between hosts at identical spec, purely from commit fsync latency. Benchmark your own target and trust ratios over absolute values.
Four locking strategies I compared
- Global lock. One advisory lock, every append serializes. Consistent, plain
uint64cursor, simple. Throughput-capped. - Per-boundary locks. A lock per
(type, tag, value), so different entities append in parallel. Fast, but positions commit out of order, so it needs opaquexid8cursors. - Hybrid. Per-boundary locks for the check, global lock for the insert. Gap-free, but lands at global speed.
- Staging + flusher. Appends land concurrently in a
stagingbuffer; a single flusher moves them toeventsin order.
There is one design rule that makes all of this lockable: an append condition must be scoped to a boundary. It needs at least one event-type-plus-tag combination, for example UserCreated tagged user:123, which becomes the lock key. A bare type-level condition like “no UserCreated exists anywhere” has no boundary to lock on, so I disallow it. It would force a global lock over the whole type and defeat the per-boundary concurrency the other strategies rely on.
The results
The global lock is flat across overlap (about 1,250 to 1,580 appends/s) and does not scale with cores. It serializes everything. That is the baseline.
Per-boundary runs 2x to 5x faster at 0% overlap, and the gap grows with cores and concurrency, up to about 6,900 appends/s at 512 users on the big node. At 100% overlap it decays back to global, because all keys collapse into one.
The hybrid lands at roughly global speed. It gives up parallel commits to stay gap-free, which is the whole reason per-boundary was fast. Skip it.
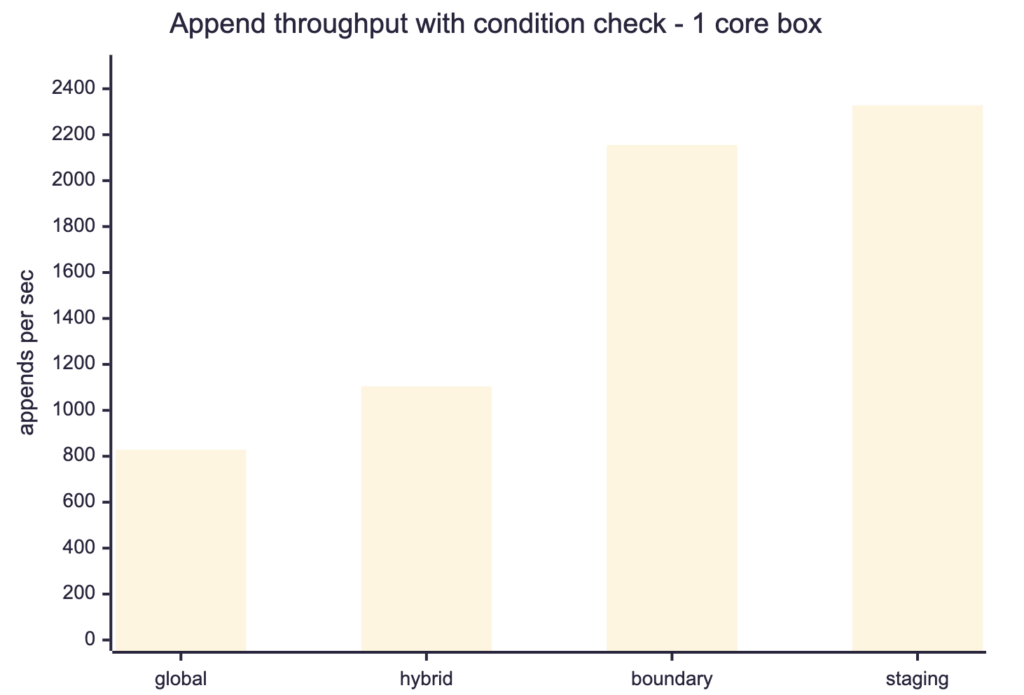
Four-way comparison on the small node, condition check on:
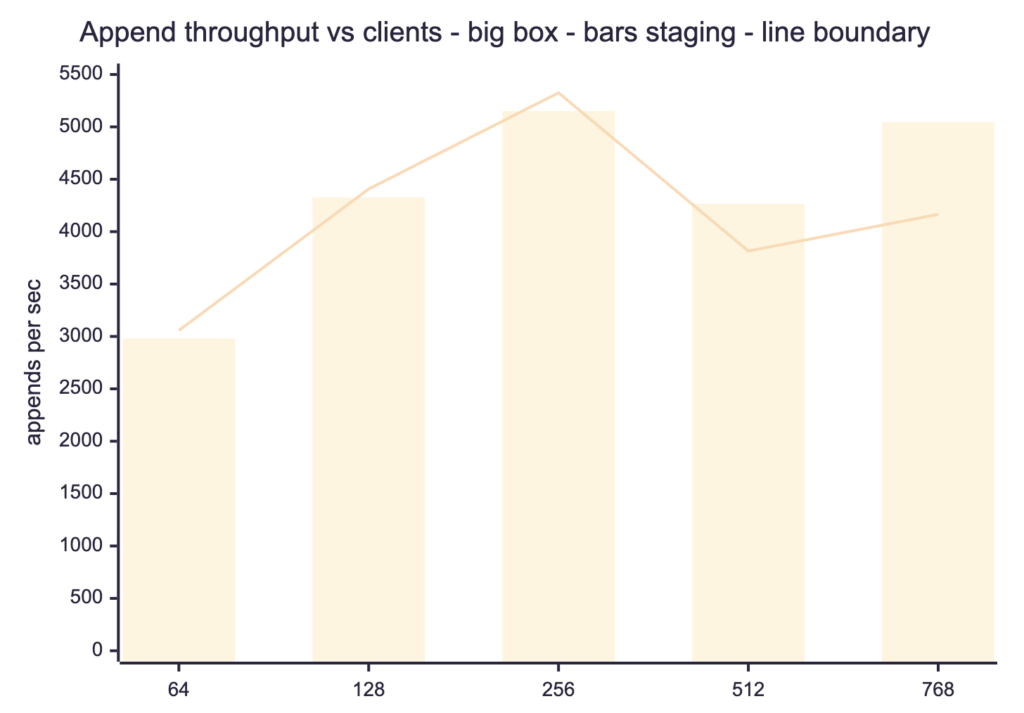
Throughput vs clients on the big node (bars staging, line boundary):
The ceiling is the database write path, not the lock: WAL plus hot-page index contention. 5K versus 15K IOPS made no difference, and disabling fsync did not raise the per-boundary ceiling.
The key insight
The problem with per-boundary locks is when the sequence number is assigned. It is allocated at insert time, before the transaction commits, and concurrent transactions commit in a different order than they took their numbers. So transaction B can grab sequence 101 and commit while transaction A still holds 100 uncommitted. A consumer tailing events by sequence number sees 101 become visible, advances its cursor past 100, and when A finally commits it has already skipped event 100. That is the gap, and it is why a plain monotonic cursor is no longer safe.
This is also why per-boundary is fast: the speed comes from many appends fsync-ing concurrently (group commit), and that concurrency is exactly what lets commit order diverge from assignment order. The hybrid serializes the commit to keep the sequence gap-free, and in doing so throws the speed away.
The per-boundary throughput is the parallel commits, and the parallel commits are the gap.
So the apparent choice is: consistency and a plain cursor (global, hybrid), or throughput (per-boundary, with opaque xid8cursors). Unless you stop serializing the write and serialize only the sequence assignment, which is what staging does.
Can we have all four properties?
That is the staging strategy. Appends land concurrently in a small staging buffer; a single flusher moves them into events in order. One writer into events keeps sequence_number gap-free and monotonic, so consumers keep a plain uint64 cursor. The condition check reads staging and events together, so it stays consistent across multiple boundaries.
| property | global | boundary | hybrid | staging |
|---|---|---|---|---|
| multi-boundary DCB | ✓ | ✓ | ✓ | ✓ |
| gap-free consistency | ✓ | ✗ | ✓ | ✓ |
plain uint64 cursor | ✓ | ✓ | ✓ | ✓ |
| per-boundary concurrency | ✗ | ✓ | ✗ | ✓ |
It is also fast: about 2.8x global on the small node, around 5,000 appends/s on the big node, and at high client counts it beats per-boundary (5,045 vs 4,165 at 768 clients), because each append hits the small staging buffer instead of the 10M-row events indexes. The flusher pays the big-index cost once per batch.
On a 100M-event table the numbers barely moved (staging peaked at 6,238/s at 256 clients) and the single flusher held the backlog at zero. The condition check short-circuits on the primary key regardless of history depth.
But it is not free
- Eventual read-visibility, which is normal event sourcing. An append lands in
stagingand appears ineventson the next flush, tens of milliseconds later. This is the eventual consistency you already have in CQRS: projections and read models always lag the write side. Staging adds a small constant to a lag you already design around. Strong-consistency decisions are unaffected, since the check readsstagingandeventstogether. - A flusher daemon. A single, always-on, leader-elected process. If it stops,
stagingfills. - About 2x write amplification. Every event is written twice. Fine for small and medium events; for large write-bound events the edge returns to per-boundary.
- A conditional ceiling on hot boundaries. A conditional append to a boundary with a pending staging row conflicts until it flushes, so roughly one conditional append per flush cycle per hot boundary. A single hammered entity gave a 42% self-conflict rate. Fine for human-paced boundaries, not for a single hot counter.
Durability holds: staging is logged, so a successful append is on disk before it returns. A crash before the flush leaves the event in staging, flushed on restart.
What about the read side?
It is out of scope by design. In event sourcing the read side is decoupled from the write side: projections are separate consumers that tail the ordered event log at their own pace and scale independently. Staging changes nothing there, since consumers tail events by the same plain cursor. The only read on the write path is the decision read, which this benchmark exercises. The read side is a separate, well-understood concern, not a gap in these numbers.
So, is DCB fast enough to stay flexible?
Yes, with limits. For spread, human-paced workloads, which is most business event sourcing, you get flexible runtime constraints, single-digit-thousands of appends per second, and full consistency with a plain integer cursor, on managed Postgres. A single hot boundary still serializes everyone, “fast enough” depends on your workload, and staging adds a flusher daemon. But the claim that DCB cannot be fast on commodity infrastructure does not hold up.